隨著水情測(cè)報(bào)技術(shù)的發(fā)展以及人工智的興起,促使數(shù)據(jù)治理和人工智能技術(shù)可以有效的融合在一起,使智能化數(shù)據(jù)治理成為可能。通過將時(shí)序大數(shù)據(jù)應(yīng)用結(jié)合機(jī)器學(xué)習(xí)技術(shù)實(shí)現(xiàn)數(shù)據(jù)挖掘和分析應(yīng)用�,從而能夠更加有效得識(shí)別哪些數(shù)據(jù)可能存在異常����。基于數(shù)據(jù)特征提取工程可實(shí)現(xiàn)對(duì)海量數(shù)據(jù)的統(tǒng)計(jì)特征�、擬合特征以及分類特征的提取,可作為實(shí)時(shí)質(zhì)控過程中應(yīng)用基礎(chǔ)規(guī)則進(jìn)行數(shù)據(jù)治理的一個(gè)有效補(bǔ)充和判斷依據(jù)�����。
通過AI實(shí)時(shí)質(zhì)控技術(shù)的應(yīng)用���,不但可以提高異常數(shù)據(jù)的分析和識(shí)別能力,還可以進(jìn)一步增強(qiáng)數(shù)據(jù)的安全管理能力和質(zhì)量控制標(biāo)準(zhǔn)�����。
AI實(shí)時(shí)質(zhì)控
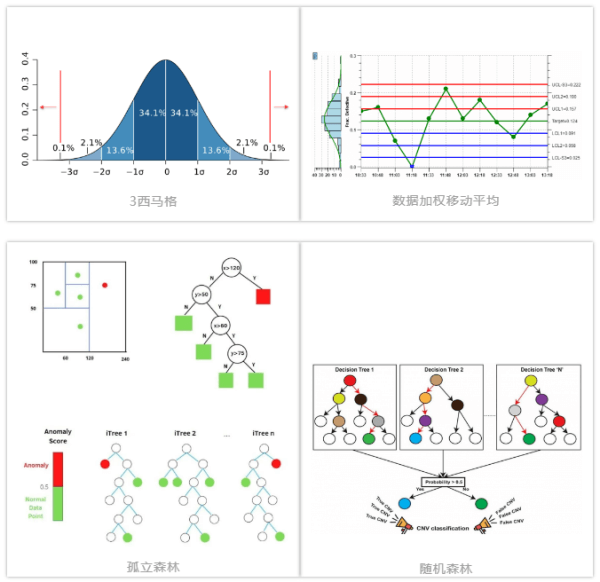
AI實(shí)時(shí)質(zhì)控包括一套默認(rèn)的算法處理流程���,主要包括3-sigma(3西格瑪)�、ewma(指數(shù)加權(quán)移動(dòng)平均)�、polynomial(多項(xiàng)式回歸)���、iforest(孤立森林)以及xgboost(優(yōu)化的分布式梯度增強(qiáng)庫(kù))5種機(jī)器學(xué)習(xí)算法,其中3-sigma���、ewma��、polynomial為統(tǒng)計(jì)判別算法�����,iforest為無(wú)監(jiān)督學(xué)習(xí)算法���,xgboost為有監(jiān)督學(xué)習(xí)算法。
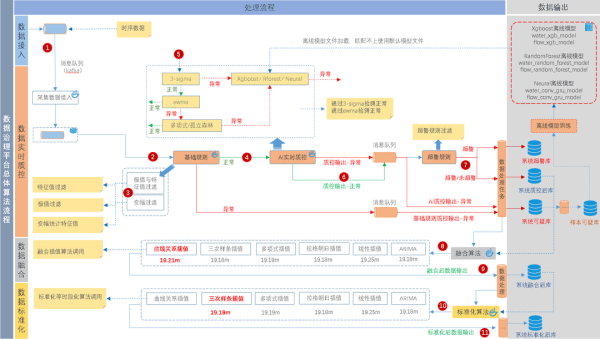
進(jìn)入AI實(shí)時(shí)質(zhì)控的數(shù)據(jù)最先通過3-sigma算法��,如果檢測(cè)正常則繼續(xù)通過ewma算法�,否則直接進(jìn)入xgboost進(jìn)行判斷,通過ewma驗(yàn)證異常則需要繼續(xù)通過多項(xiàng)式或孤立森林進(jìn)行驗(yàn)證��,如果檢驗(yàn)正常則直接輸出否則需要進(jìn)入xgboost進(jìn)行判斷���,xgboost算法庫(kù)的過濾需要依賴離線模型文件的支撐����,離線模型文件來(lái)源于質(zhì)控打標(biāo)工具的成果輸出,既可以使用系統(tǒng)默認(rèn)的離線模型�����,也可以使用針對(duì)不同測(cè)站訓(xùn)練好的模型文件����。可根據(jù)數(shù)據(jù)的不同應(yīng)用場(chǎng)景來(lái)對(duì)算法的組合進(jìn)行調(diào)整�����,確保最佳的算法質(zhì)控效果�����。
實(shí)時(shí)AI質(zhì)控處理流程
實(shí)時(shí)AI質(zhì)控一站一策
特征工程指標(biāo)提取與趨勢(shì)分析
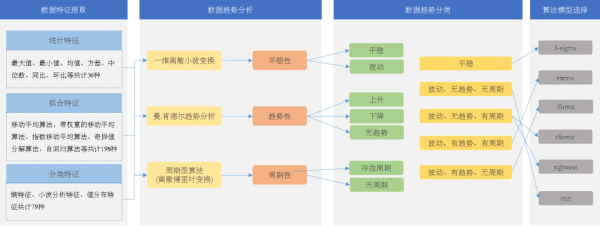
水工程水情的實(shí)時(shí)質(zhì)控?cái)?shù)據(jù)量很大�,通過人工過濾樣本數(shù)據(jù)的手段相對(duì)低效�����,所以我們?cè)谀P陀?xùn)練工程中引入了時(shí)序數(shù)據(jù)特征提取工具庫(kù)�,能夠提取出超過100多種特征指標(biāo),還可以依據(jù)專家經(jīng)驗(yàn)來(lái)豐富特征值庫(kù)的各種指標(biāo)項(xiàng)�����,根據(jù)不同的業(yè)務(wù)場(chǎng)景對(duì)不同的特征指標(biāo)分類進(jìn)行排列組合,以達(dá)到最佳的質(zhì)控訓(xùn)練效果�。
在基礎(chǔ)規(guī)則、變幅規(guī)則�、部分場(chǎng)景規(guī)則等現(xiàn)有業(yè)務(wù)質(zhì)控指標(biāo)的基礎(chǔ)上疊加特征工程能進(jìn)一步提升數(shù)據(jù)質(zhì)控的質(zhì)量。通過特征工程中的統(tǒng)計(jì)特征����、分類特征和擬合特征可充分實(shí)現(xiàn)對(duì)長(zhǎng)序列歷史時(shí)序數(shù)據(jù)平穩(wěn)性、趨勢(shì)性及周期性的分析���,依此分析結(jié)果可將看似毫無(wú)規(guī)律可循的數(shù)據(jù)集進(jìn)行分類匯總�����,實(shí)現(xiàn)數(shù)據(jù)分類的目的��,進(jìn)而選取不同的模型算法組合�。
通過特征工程極大得提升了數(shù)據(jù)檢出的指標(biāo)依據(jù)��,同時(shí)為站點(diǎn)間相似特征的統(tǒng)計(jì)分類提供了必要的能力支撐��,便于后續(xù)不同站點(diǎn)相關(guān)關(guān)系的抽取和聚合。
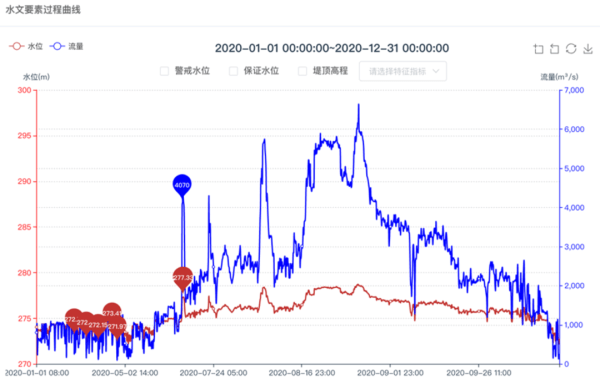
數(shù)據(jù)趨勢(shì)分析主要對(duì)提取特征后的時(shí)序數(shù)據(jù)實(shí)現(xiàn)數(shù)據(jù)平穩(wěn)性���、趨勢(shì)性和周期性的分析��,采用不同的趨勢(shì)分析算法實(shí)現(xiàn)數(shù)據(jù)的趨勢(shì)性結(jié)果分析��。
根據(jù)數(shù)據(jù)趨勢(shì)分析的成果�,將時(shí)序數(shù)據(jù)分成不同的類別�����,并采用不同的算法對(duì)分類后的數(shù)據(jù)進(jìn)行異常檢測(cè)���,通常情況下����,一類數(shù)據(jù)可使用多種算法選擇性得進(jìn)行檢測(cè)�����,這里采用的最優(yōu)算法�����,主要對(duì)數(shù)據(jù)的檢出時(shí)效性和準(zhǔn)確性綜合進(jìn)行評(píng)估����。
特征值提取與趨勢(shì)分析
離線模型訓(xùn)練與樣本標(biāo)記
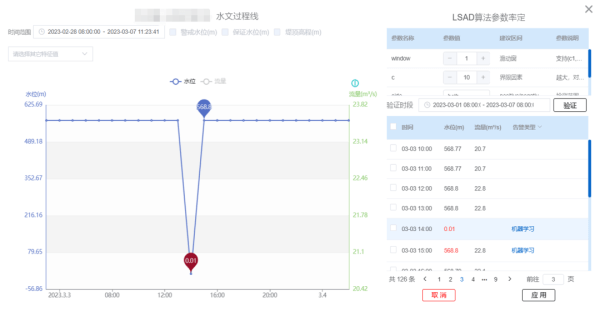
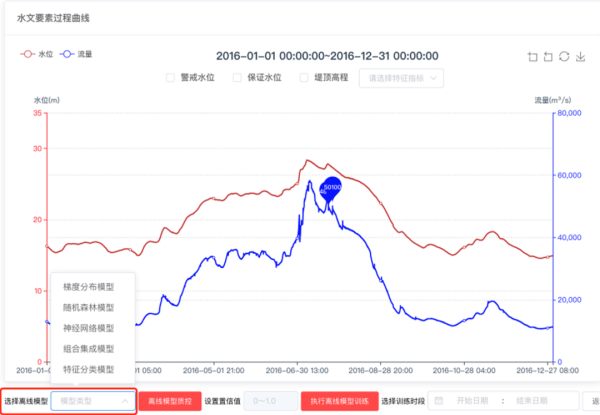
通過質(zhì)控打標(biāo)工具可實(shí)現(xiàn)選擇站點(diǎn)與訓(xùn)練時(shí)段、標(biāo)記可疑數(shù)據(jù)����、檢出數(shù)據(jù)分析結(jié)果以及離線模型訓(xùn)練功能,結(jié)合不同測(cè)站的不同數(shù)據(jù)特征可選擇不同的離線模型�,如梯度分布模型、隨機(jī)森林模型�、神經(jīng)網(wǎng)絡(luò)模型、特征分類模型等����,通過手動(dòng)標(biāo)記負(fù)樣本的方式來(lái)實(shí)現(xiàn)離線模型訓(xùn)練的樣本收集工作,負(fù)樣本越少模型的訓(xùn)練時(shí)間越短�,訓(xùn)練出來(lái)的模型質(zhì)量越低,負(fù)樣本越多訓(xùn)練出來(lái)模型的質(zhì)控精度就會(huì)越高�。
訓(xùn)練完成的模型文件將在線進(jìn)行更新,當(dāng)您再次選擇采用離線模型再次進(jìn)行質(zhì)控驗(yàn)證的時(shí)候�����,使用的將是您剛剛訓(xùn)練好的最新模型文件�。通過負(fù)樣本數(shù)據(jù)的不斷積累、模型訓(xùn)練次數(shù)的不斷提升,輸出模型的精準(zhǔn)率也會(huì)越來(lái)越高��。
負(fù)樣本標(biāo)記
離線模型訓(xùn)練

 400-8838-199
400-8838-199 info@four-faith.com
info@four-faith.com 廈門集美區(qū)軟件園三期B區(qū)B14棟5層
廈門集美區(qū)軟件園三期B區(qū)B14棟5層 閩公網(wǎng)安備 35021102000914號(hào)
閩公網(wǎng)安備 35021102000914號(hào)
 樣機(jī)免費(fèi)試用
確保四信物聯(lián)網(wǎng)rtu產(chǎn)品深度契合貴司業(yè)務(wù)需求
樣機(jī)免費(fèi)試用
確保四信物聯(lián)網(wǎng)rtu產(chǎn)品深度契合貴司業(yè)務(wù)需求




